Tento týždeň som na sústredení KSP - no update.
Tento týždeň plánujeme naplánovať a vykonať experimenty one-shot promptingu, ukázať, či sa nad naším datasetom dá testovať aj few-shot prompting a aspoň pripraviť experimenty na chain-of-thought zero-shot prompting.
Z písomnej časti uzavrieme úvodnú kapitolu a doplníme dosiahnuté výsledky zo zero-shot promptingu, ktoré sme prezentovali minulý ťýždeň na ŠVK.
Update k ŠVK: boli sme pozvaní, aby sme reprezentovali fakultu na medzištátnom kole ŠVOČ v Olomouci 26.-28.mája, ak sa všetko podarí, zúčastníme sa.
Minulý týždeň sa dokončilo spracovanie zero-shot výsledkov, písanie sa nám až tak nepodarilo, keďže veľa času sa venovalo príprave na ŠVK.
Tento týždeň sme sa zúčastnili s našou prácou na ŠVK, na ktorej sme sa stali laureátmi ŠVK v sekcii Informatika.
Minulý týždeň sme úspešne dokončili zero-shot experimenty nad fyzikálnou častou datasetu a pripravili experimenty nad programovaciou časťou.
Tento týždeň chceme dokončiť spracovávanie zero-shot výsledkov, spísať informácie o riešeniach v datasetoch a dokončiť niektoré časti introduction kapitoly.
Podarilo sa nám minulý týždeň dokončiť testovací framework a spusiť už aj prvé testy nad matematickou časťou datasetu.
Zároveň som takmer dopísal kapitolu o našom datasete, zostáva spísať ešte nejaké informácie o riešeniach úloh, ktoré v datasete máme.
Tento týždeň venujeme jednak príprave príspevku na ŠVK, a dokončením zero-shot experimentov nad našimi úlohami.
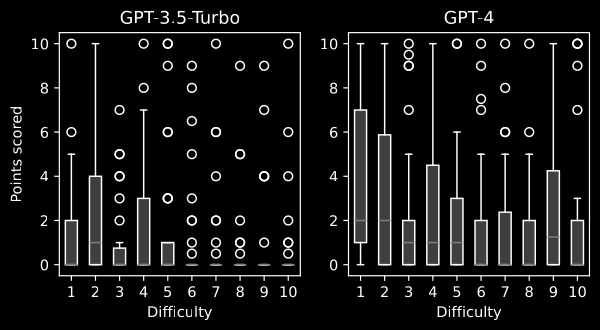
Zatiaľ sme testovali naše úlohy na modeloch GPT-4 a GPT-3.5-Turbo. Priemerné ohodnotenie v matematických príkladoch je 1.24/10 pre GPT-3.5-Turbo a 2.26 pre GPT-4. Okrem toho, že GPT-4 dosahuje všeobecne lepšie výsledky ako GPT-3.5-Turbo, možno si všimnúť, že v jednoduchších príkladoch je tento rozdiel výraznejší.
LLM niekedy produkujú výsledky v angličtine a nie v slovenčine, napriek tomu nie je výrazný rozdiel v dosahovaných bodoch medzi výstupnými jazykmi (priemer 🇸🇰: 1,72; 🇬🇧: 1,62). Ďalej sme testovali, čo sa stane ak preložíme zadania do slovenčiny a pošleme modelu takto preložené úlohy. Toto sme skúšali zatiaľ len na malej podmnožine nášho datasetu (n=35). Výsledky nenaznačujú žiadny vplyv na dosiahnuté body (priemer 🇸🇰: 0,60; 🇬🇧: 0,58).
Minulý týždeň sa začala práca na testovaciom frameworku, ktorý by sme chceli tento týždeň dokončiť.
Okrem toho cez týždeň chceme dopísať kapitolu popisujúcu vlastnosti, úlohy a obsah nášho datasetu - nejaké popisy, čo vlastne náš dataset obsahuje, nejaké štatistické informácie, príklady a celkový prehľad.
Začiatkom týždňa som sfinalizoval dataset príkladov. Začal som experimentovať s GPT-3.5-Turbo, zatiaľ veľmi priamočiaro. Cez týždeň sa budem venovať príprave nástrojov a frameworku na automatizáciu experimentov nad datasetom.
Začiatkom týždňa sa našli ešte nejaké ďalšie príklady, takže tento týždeň sme venovali dokončeniu a finalizácií nášho datasetu. Okrem toho sa mi podarilo pohnúť s obsahom kapitol o datasete a doplniť informácie o zlyhaniach experimentálnej extrakcie textu pomocou nástroja Nougat. Cez týždeň sme ešte pripravovali prístupy k rozhraniu OpenAI.
Pokračujeme v klasifikácií úloh, so školiteľom sme si prešli návrhy mojich experimentov na datasete. Cez víkend vyberieme zopár úloh a skúsime na nich pripraviť a spustiť experimenty voči gpt-3.5-turbo.
Tento týždeň venujeme klasifikácií úloh v našom datasete a návrhu úvodných experimentov, aby sme už mohli niečo dať modelom.
Priebežne pokračujem v dokumentácií prior work v oblasti vyhodnocovania výsledkov.
Máme veľkú časť datasetu pripravenú. Skúšame, či by sa nedali niektoré PDF zadania prekonvertovať do TeXu/Markdownu.
Nástroj Nougat vyzerá ako sľubné riešenie, avšak na mne dostupných zariadeniach je pomerne pomalý (~5 min/str.). Pokúšame sa ho rozbehať na výkonnejšiom serveri.
So školiteľom sme sa stretli vo štvrtok, vyriešili sme prístupy na GPU server pre behanie Nougat-u.
Prediskutovali sme existujúce spôsoby hodnotenia výstupov LLM. Do ďalšieho stretnutia spíšem, čo skúšali ľudia pred nami a skúsim poklasifikovať úlohy v našom datasete podľa toho, či vedú k číselným výsledkom. Ideálne ešte stihnem pripraviť návrh experimentov, aby sme budúci týždeň už vedeli niečo dať modelom.
✅ - hotovo, ⭕️ - aktuálne prebieha.